MPI¶
Note
Cette documentation traite la parallélisation MPI réalisée dans le code MARS. Elle explique le formalisme employé et l’utilisation de l’interface (module toolmpi.F90) entre la bibliothèque MPI elle-même et le code MARS. Pour une explication sur la bibliothèque MPI elle-même, il est fortement conseillé de suivre les formations de l’idris ou à défaut d’éplucher leurs cours qui sont très didactiques et peuvent être étudiés en toute autonomie. Merci à l’équipe de formation de l’Idris qui nous a autorisé à reprendre une partie de leur cours.
L’essentiel l’introduction de la parallélisation MPI du code MARS a été effectuée par Tina Odaka (auteur de toolmpi.F90, interface entre le code MARS et la bibliothèque MPI) puis par Akiko et Valérie Garnier.
Présentation de MPI¶
MPI (Message Passing Interface)
- Paradigme de parallélisation pour architectures à mémoire distribuée basé sur l’utilisation d’une bibliothèque portable.
- MPI est basé sur une approche de communications entre processus par passage de messages car chaque éxécutable réalise l’ensemble du programme sur un domaine particulier.
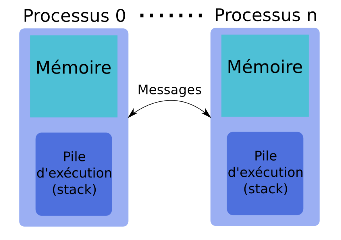
idris (Lavallée & Wautelet)
Limitation de MPI¶
- L’accélération finale est limitée par la partie purement séquentielle du code.
- Les surcoûts liès à la bibliothèque MPI et la gestion de l’équilibrage de charge limitent l’extensibilité.
- Certains types de communications collectives prennent de plus en plus de temps lorsque le nombre de processus augmente (par exemple MPI_Alltoall).
- Pas de distinction entre processus tournant en mémoire partagée ou distribuée.
Warning
Une approche incrémentale de la parallélisation du code est impossible.
Compilation¶
La documentation concernant la compilation du code avec MPI ou MPT est disponible sous XXXXX.
Note
Il est nécessaire d’avoir compilé la librairie NetCDF4 an parallèle au préalable.
Lancement d’un job MPI sur Caparmor¶
- ::
- runmpi_connect name_run champs 256 0
runmpi_connect name_run name_file number_cpu number_omp type_file [concatdir]
- name_run: visible from qstat command
- name_file: ‘name defined in output.dat’_’suffix defined in paracom.txt’
- number_cpu: total number of cpus (MPI+OMP)
- type_file: * 0 (no gathering because l_out_nc4par=.true.) * 1 (all records in one file) * 2 (a record by file)
- concatdir (optional): path where you will create the global file. To gather files faster, it is better to write CPU parts into a global file created under a /home directory.
A l’éxécution, si aucun fichier spécifiant la répartition spatiale des noeuds (fichier mpi.txt) n’est disponible auprès de l’éxécutable, le code MARS découpe le domaine en bandes verticales (imax>jmax) ou horizontales (jmax>imax). L’équilibrage de charge entre les différents processus est assuré par le code MARS qui cherche à équilibrer le nombre de cellules mouillées entre chaque domaine MPI.
Décomposition en domaines¶
Pour obtenir un fichier mpi.txt et utiliser un découpage MPI en 2 dimensions (i/j), il faut utiliser le programme decoupe. Une description du programme decoupe lui-même est disponible ici.
L’éxécutable compilé en MPI s’éxécute sur différents processus de manière indépendante. Dans le cas de MARS, un processus est affecté à une région (limin:limax,ljmin:ljmax).
Les domaines sont numérotés ainsi:
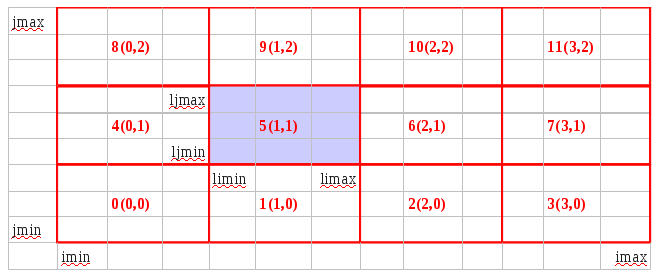
On retrouve ces numéros dans mpidebugprepare écrit par toolmpi.F90 pour sauver le décompage MPI utilisé par le run.
On retrouve aussi ces numéros dans les extensions des fichiers de sortie (l_out_nc4par=.False.):
champs_V10.nc.000.000
champs_V10.nc.000.001
champs_V10.nc.000.002
...
champs_V10.nc.001.001
...
champs_V10.nc.003.002
Ces extensions sont ajoutés au nom des fichiers par la commande:
CALL_MPI ADD_TAG(filename,LEN(filename))
Formalisme dans MARS¶
La mémoire étant distribuée, chaque processus n’a pas accès à la mémoire des autres processus.
Chaque sous-domaine (calculé par le même processus tout au long de la simulation) est défini par des indices locaux limin/limax et ljmin/ljmax.
Pour les calculs faisant intervenir plusieurs indices (gradients...), il faut que les domaines se recouvrent et que les valeurs des variables situées dans les zones de recouvrement soient échangées.
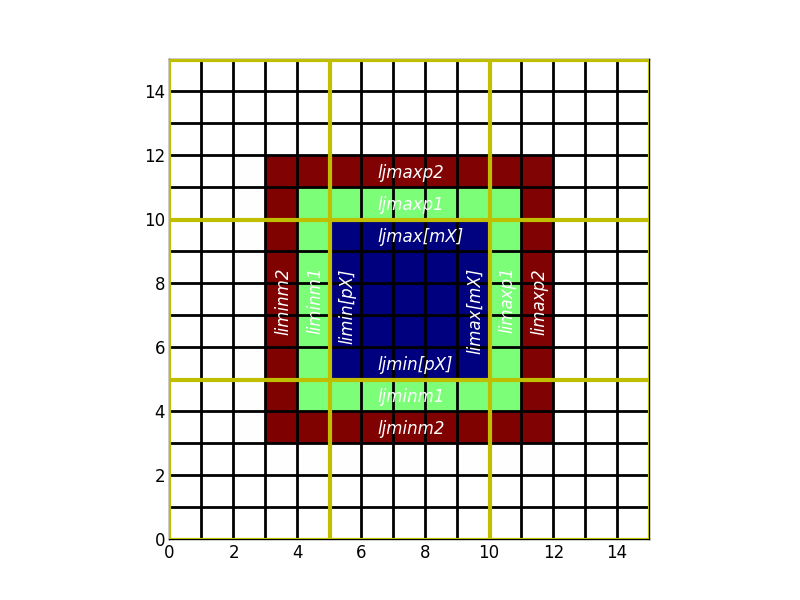
D’où les variables, limaxp2,ljminm1...
En dehors des frontières ouvertes de la configuration, la taille du recouvrement est définie par
- pX : à l’est et au nord
- mX : à l’ouest et au sud
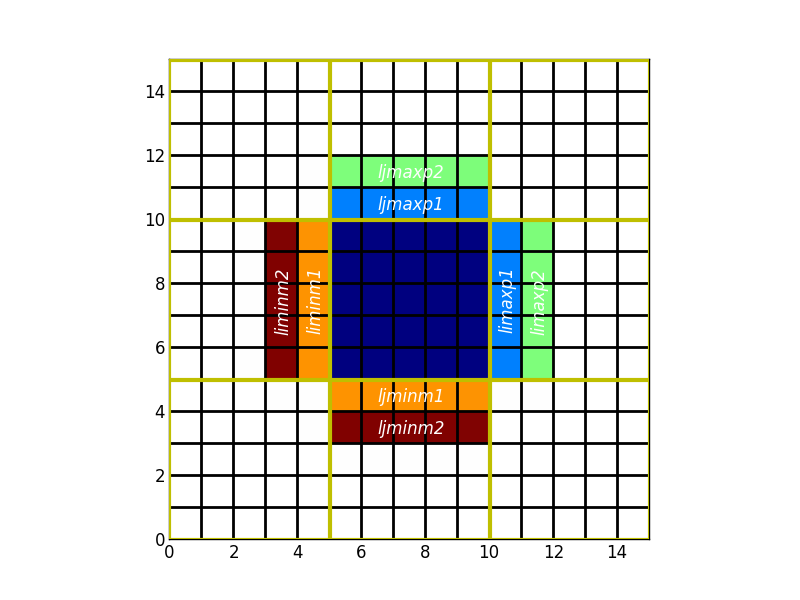
Le long des frontières ouvertes, la signification est différente:
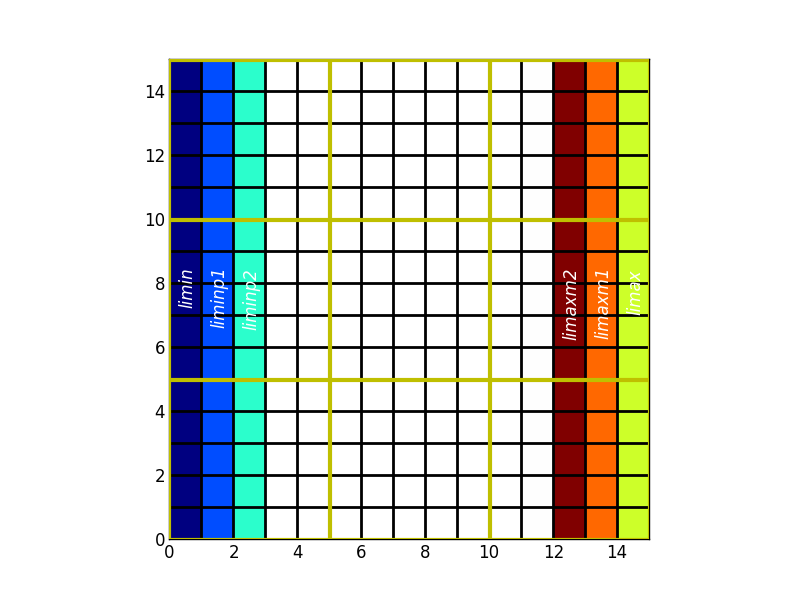
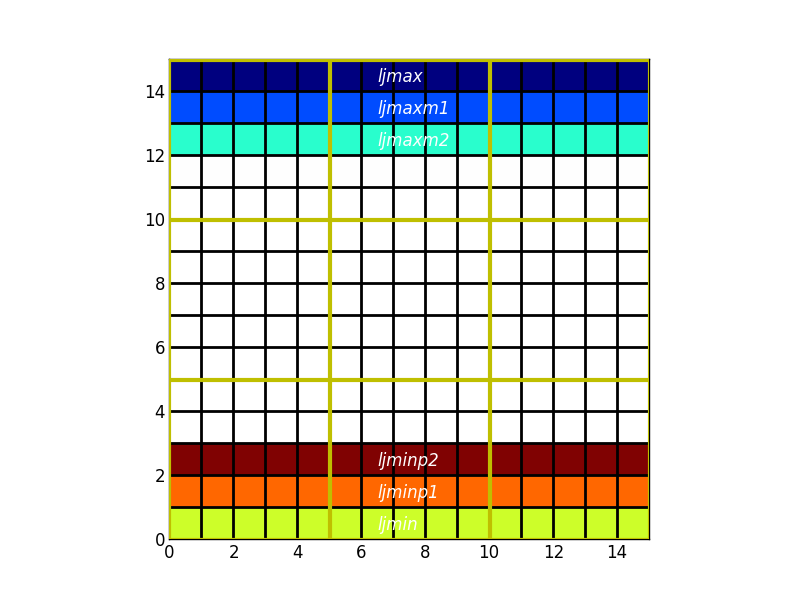
En dehors des cas ci-dessus, les cellules ne se situent pas à l’extérieur du domaine défini par limin:limax ljmin:ljmax. Les valeurs de l*minpX valent l*min tandis que celles de l*maxpX valent l*max
Dimensions des tableaux¶
Comment dimensionner un tableau ?
Dans MARS, la taille de la matrice associée à une variable, plus exactement du recouvrement, dépend directement des indices utilisés pour une variable.
- Si le plus grand indice utilisé selon x est ‘i+3’, le tableau sera défini jusqu’à ‘limaxp3’
- Si le plus petit indice utilisé selon y est ‘i-1’, le tableau sera défini dès ‘ljminm3’
Pour repérer les indices utilisés dans l’ensemble du code, un outil python est disponible sous $HOMEMARS/TOOLS/PARSERVAR/varanalyse.py
python varanalyse.py -v "ssh,xe2,xe3,uz,ustar" [-o mpi_parser] -d $CDIR/WCONF-CASE/WORK
Cette commande donne le fichier mpi_parser.ods
- pour chaque variable est noté le nom de la routine dans laquelle on utilise l’indice précisé dans chaque colonne. Le repérage des indices utilisés permet de connaître l’extension spatiale nécessaire.
- La variable est instanciée dans les routines écrites en gras et permet de repérer où doivent être insérrés les échanges MPI.
Warning
Il ne faut pas oublier de parser les différents noms de la même variable (quand elle est passée en argument notamment)
Exemple : ssh, xe2, xe3...
Note
Un autre outil marsparser.py scanne l’ensemble du code variable par variable. Extrêmement long et tableau récapitulatif final énorme.
Echanges¶
Où placer les échanges ?
Par choix et simplicité de codage, les échanges MPI se font juste après l’instanciation.
Comment faire un échange MPI
- cas classique
CALL_MPI ex_i_int(mX,pX,kdim,liminm1,limax,ljmin,ljmax,mo(liminm1:limax,ljmin:ljmax))
CALL_MPI ex_i_int(-1,0,1,liminm1,limax,ljmin,ljmax,mo(liminm1:limax,ljmin:ljmax))
**mX**: nombre de cellules à gauche, (-2 si liminm2)
**pX**: nombre de cellules à droite, (+1 si limaxp1)
**kdim**: dimension verticale du tableau (1, kmax ou kmax+1)
les autres indices sont les dimensions horizontales des tableaux
CALL_MPI devient CALL après le pré-processing en présence de la clef cpp -Dkey_MPI_2D. Sinon, cela devient !CALL_MPI
| name of the routine | type of the variable | direction |
|---|---|---|
| ex_i_int | INTEGER | along X |
| ex_i_rsh | REAL(KIND=4) | along X |
| ex_i_rlg | REAL(KIND=8) | along X |
| ex_j_int | INTEGER | along Y |
| ex_j_rsh | REAL(KIND=4) | along Y |
| ex_j_rlg | REAL(KIND=8) | along Y |
- échanges selon les 2 directions
CALL_MPI ex_i_rsh(-2,2,1,liminm2,limaxp2,ljminm2,ljmaxp2,ssh(liminm2:limaxp2,ljminm2:ljmaxp2))
CALL_MPI ex_j_rsh(-2,2,1,liminm2,limaxp2,ljminm2,ljmaxp2,ssh(liminm2:limaxp2,ljminm2:ljmaxp2))
CALL_MPI ex_i_rsh(-1,2,kmax,liminm1,limaxp2,ljminm1,ljmaxp2,temp(:,liminm1:limaxp2,ljminm1:ljmaxp2))
CALL_MPI ex_j_rsh(-1,2,kmax,liminm1,limaxp2,ljminm1,ljmaxp2,temp(:,liminm1:limaxp2,ljminm1:ljmaxp2))
Note
Toujours faire les échanges dans l’ordre i puis j
- Explication de l’effet des routines ex_i_TYPE et ex_j_TYPE
CALL ex_i_rsh(0, +b, kmax, yimin, yimax, ljmin, ljmax, Y(1:kmax, yimin:yimax, ljmin:ljmax))
CALL ex_j_rsh(0, +d, kmax, yimin, yimax, yjmin, yjmax, Y(1:kmax, yimin:yimax, yjmin:yjmax))
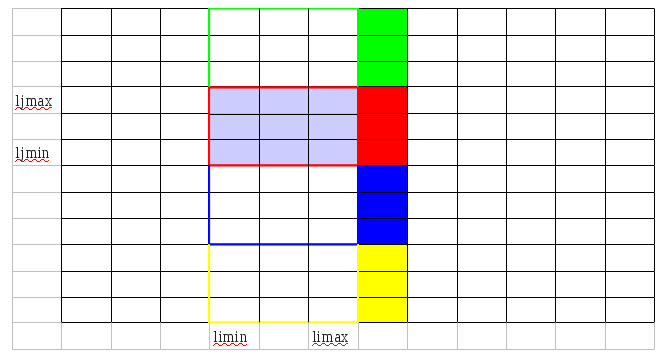
Le process(Pi,Pj) reçoit les données Y(:, limax+1:limax+b, ljmin:ljmax) du processus (Pi+1,Pj) (en rouge sur la figure ci-dessus). Les processus (Pi,Pj-1) et (Pi,Pj+1) procèdent de la même manière et reçoivent les données en vert et bleu respectivement.
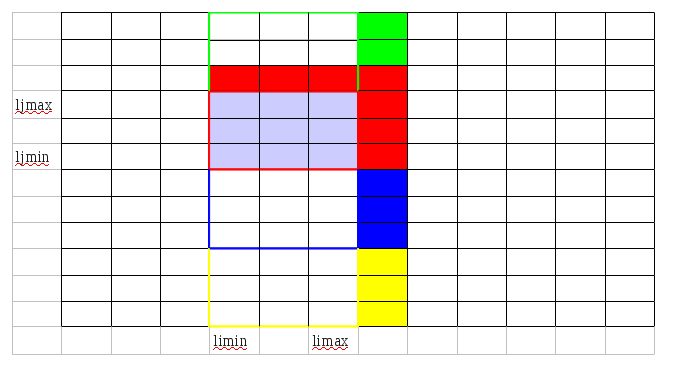
Le processus (Pi,Pj) reçoit les données Y(:, limin:limax+b, ljmax+1:ljmax+d) du processus (Pi,Pj+1) (encadré rouge sur la figure ci-dessus). The received data are filled by red. Le processus (Pi, Pj+1) a déjà les données dont il a besoin.
Note
La gestion des variables yimax,yimin,yjmax,yjmin était une telle source d’erreur que maintenant dès l’appel de ex_j_TYPE on donne les dimensions locales du tableaux.
- conditions aux limites périodiques
CALL_MPI ex_peri_x_rsh(2,kmax,liminm1,limaxp2,ljminm1,ljmaxp2,temp(:,liminm1:limaxp2,ljminm1:ljmaxp2))
CALL_MPI ex_peri_y_rsh(2,kmax,liminm1,limaxp2,ljminm1,ljmaxp2,temp(:,liminm1:limaxp2,ljminm1:ljmaxp2))
Ces routines sont disponibles depuis la routine toolmpi.F90 qui est une interface entre le code MARS et la bibliothèque MPI.
Warning
on ne peut échanger que des variables partagées (déclarées dans un module ou common)
Remarque: Ce choix de formalisme n’est en fait pas idéal:
- Il eut peut-être mieux valu utiliser des ghostcells identiques quelques soient les variables
- Surtout, il faudrait rassembler les échanges au maximum
Spécificité ADI¶
dyn2dxy.F90:
CALL_MPI transpose_col
CALL_MPI trback_col(xeuv)
dyn3dxy.F90:
CALL_MPI transpose_row
CALL_MPI trback_row(xeuv)
Communications collectives et Réductions¶
Extrait du cours de l’idris (Dupays, Flé, Gaidamour, Lecas)
- Une réduction est une opération appliquée à un ensemble d’éléments pour en obtenir une seule valeur. Des exemples typiques sont la somme des éléments d’un vecteur SUM(A(:)) ou la recherche de l’élément de valeur maximum dans un vecteur MAX(V(:)).
- MPI propose des sous-programmes de haut-niveau pour opérer des réductions sur des données réparties sur un ensemble de processus. Le résultat est obtenu sur un seul processus (MPI_REDUCE() ) ou bien sur tous (MPI_ALLREDUCE() , qui est en fait équivalent à un MPI_REDUCE() suivi d’un MPI_BCAST() ).
Exemple de réduction (produit) avec diffusion des résultats.
program allreduce
use mpi
implicit none
integer :: nb_procs,rang,valeur,produit,code
call MPI_INIT (code)
call MPI_COMM_SIZE ( MPI_COMM_WORLD ,nb_procs,code)
call MPI_COMM_RANK ( MPI_COMM_WORLD ,rang,code)
if (rang == 0) then
valeur=10
else
valeur=rang
endif
call MPI_ALLREDUCE (valeur,produit,1, MPI_INTEGER , MPI_PROD , MPI_COMM_WORLD ,code)
print*,'Moi, processus ',rang,', j''ai reçu la valeur du produit global ',produit
call MPI_FINALIZE (code)
end program allreduce
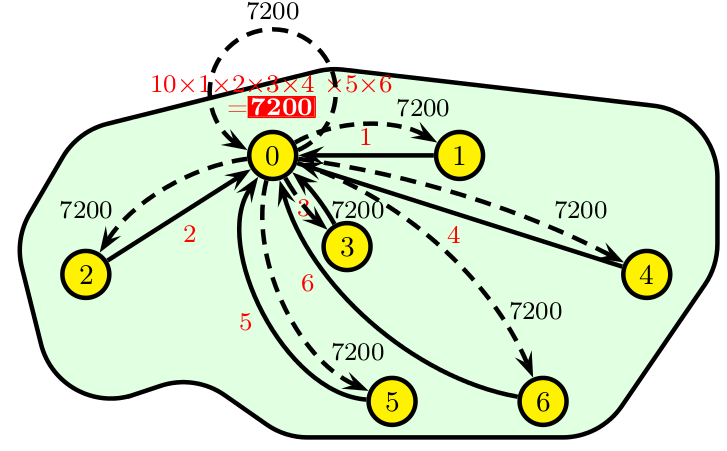
idris (Dupays, Flé, Gaidamour, Lecas)
Liste des réductions principales disponibles dans la bibliothèque MPI:
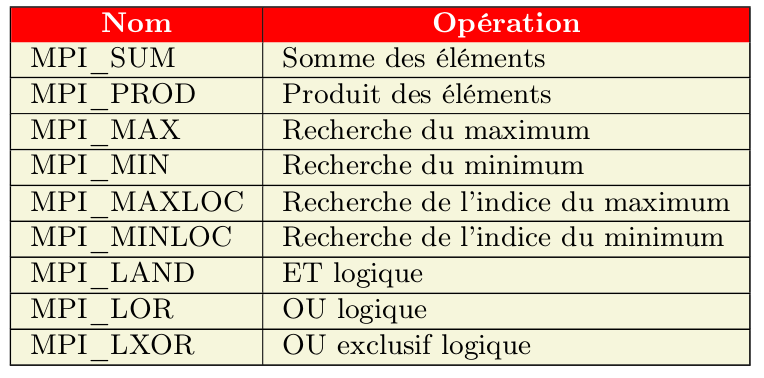
idris (Dupays, Flé, Gaidamour, Lecas)
Diagnostiques¶
Dans l’interface MPI / MARS (module toolmpi.F90), les routines de réductions collectent les résultats de tous les processus et il y a diffusion à tous les processus dès qu’il y a ALL dans le nom (sauf pour ADD_ZONAL_RSH)
- Somme
Les routines permettant de faire la somme d’un réel ou entier commencent par ADD_MPI
| name of the routine | argument | portée |
|---|---|---|
| ADD_MPI_INT | (local,total) | REDUCE |
| ADD_MPI_RSH | (local,total) | REDUCE |
| ADD_MPI_RLG | (local,total) | REDUCE |
| ADD_ALL_MPI_INT | (local2global) | ALLREDUCE |
| ADD_ALL_MPI_RSH | (local2global) | ALLREDUCE |
| ADD_ALL_MPI_RLG | (local2global) | ALLREDUCE |
| ADD_ZONAL_RSH | (mine,mind1,maxd1,mind2,maxd2,comm1d) | ALLREDUCE |
Note
La parallelisation MPI change necessairement les resultats par rapport au cas sequentiel (car sommes effectuees dans ordres differents)
Moyenne
- faire la somme de la valeur sur l’ensemble du domaine global (donc sur l’ensemble des processus)
- faire la somme des aires (par example) ou récupérer le nombre total de processus (USE toolmpi, ONLY : NPROCS)
- diviser la somme de la valeur par la somme des processus
SUBROUTINE average(COMM_ZONAL,comm2dverif)
USE parameters, ONLY : ljminp2,ljmaxm1,limin,limax,ishift_obc_west,ishift_obc_east,valmanq
USE toolmpi, ONLY : ADD_ALL_MPI_RSH, ADD_ALL_MPI_RSH
REAL(KIND=rsh) :: mssh,area
mssh=0.0
area=0.0
do j=ljminp2,ljmaxm1
do i=MAX0(limin,2+ishift_obc_west), MIN0(limax,imax-1-ishift_obc_east)
IF (h0(i,j) > -valmanq) THEN
cff1=surf(i,j)
mssh=mssh+cff1*ssh(i,j)
area=area+cff1
END IF
enddo
enddo
CALL ADD_ALL_MPI_RSH(mssh)
CALL ADD_ALL_MPI_RSH(area)
mssh=mssh/area
END SUBROUTINE average
Note
La parallelisation MPI change necessairement les resultats par rapport au cas sequentiel (car sommes effectuees dans ordres differents)
- Min / Max
| name of the routine | argument | portée |
|---|---|---|
| MAX_ALL_MPI_INT | (local2global,comm_active) | ALLREDUCE |
| MAX_ALL_MPI_RSH | (local2global,comm_active) | ALLREDUCE |
| MIN_ALL_MPI_INT | (local2global,comm_active) | ALLREDUCE |
| MIN_ALL_MPI_RSH | (local2global,comm_active) | ALLREDUCE |
| FINDMAX_MPI | (cflumax,iumax,jumax,uzmax,htxmax,dxumax) | special pour dyn3ddt |
Output¶
Toutes les opérations effectuées par MPI portent sur des communicateurs. Le communicateur par défaut est MPI_COMM_WORLD (=MPI_COMM_MARS) et il comprend tous les processus actifs.
idris (Dupays, Flé, Gaidamour, Lecas)
Si l’on souhaite ne sauver qu’une partie du domaine (spécifié dans output.dat), il est possible que des processus ne soient pas concernés par l’écriture.
Il faut donc partitionner un ensemble de processus afin de créer des sous-ensembles sur lesquels on puisse effectuer des opérations telles que des communications MPI. Chaque sous-ensemble ainsi créé aura son propre espace de communication.
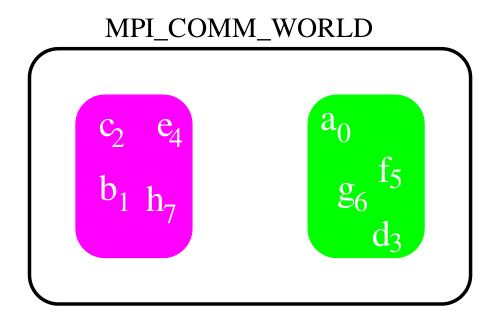
idris (Dupays, Flé, Gaidamour, Lecas)
Creation d’un communicateur dans MARS:
SUBROUTINE output_save
USE toolmpi, ONLY : ADD_TAG,IPROC,NPROCS,ADD_ALL_MPI_INT
IMPLICIT NONE
INCLUDE 'mpif.h'
INTEGER :: i,j,k,l
INTEGER :: grp_world,grp_zoom,comm_zoom,ncpu,ip,ierr_mpi
INTEGER, DIMENSION(:), ALLOCATABLE :: numrank,listrank
!!----------------------------------------------------------------------
!! * Executable part
comm_zoom=MPI_COMM_WORLD
!IF ( ( (nbouc == 0 .AND. .NOT.l_filebydate(nb)) .OR. (l_filebydate(nb) .AND. tect >= tsort(nb)) ) .AND. l_out_nc4par ) THEN
IF ( (nbouc == 0 .AND. .NOT.l_filebydate(nb)) .OR. (l_filebydate(nb) .AND. tect >= tsort(nb)) ) THEN
! what a code ! Not a clever code probably but not clear in my head at the moment
! Count the number of processors active over the area to be saved
ncpu=0
IF ( jextmin(nb) <= jextmax(nb) .AND. iextmin(nb) <= iextmax(nb) ) ncpu=ncpu+1
CALL ADD_ALL_MPI_INT(ncpu)
! Save the number of active processors
ALLOCATE (numrank(ncpu))
ALLOCATE (listrank(nprocs))
numrank(:)=0 ! must be initialized if the proc 0 is active on the saved zoom
listrank(:)=0
! which cpu is active ?
IF ( jextmin(nb) <= jextmax(nb) .AND. iextmin(nb) <= iextmax(nb) ) listrank(1)=iproc
! all cpus get the number of active cpus plus sleeping cpus (set to 0)
CALL MPI_ALLGATHER(listrank(1),1,MPI_INTEGER,listrank,1,MPI_INTEGER,MPI_COMM_WORLD,ierr_mpi)
! all cpus keep the active cpus only
IF (ncpu/=nprocs) THEN
ip=0
DO i=1,nprocs
IF ( listrank(i) /= 0 ) THEN
ip=ip+1
numrank(ip)=listrank(i)
ENDIF
END DO
! Group relative to the MPI_COMM_WORLD: on récupère le groupe du communicateur MPI_COMM_WORLD
CALL MPI_COMM_GROUP(MPI_COMM_WORLD,grp_world,ierr_mpi)
! Create the group of active cpus
CALL MPI_GROUP_INCL(grp_world,ncpu,numrank,grp_zoom,ierr_mpi)
! Create the new communicator COMM_ZOOM
CALL MPI_COMM_CREATE(MPI_COMM_WORLD,grp_zoom,comm_zoom,ierr_mpi)
ENDIF
ENDIF
IF ( jextmin(nb) <= jextmax(nb) .AND. iextmin(nb) <= iextmax(nb) ) THEN
!-----------------------
! create the ouput files
!-----------------------
IF (l_out_nc4par) THEN
! To allow the different cpus to write at the same time into a global
! file, set l_out_nc4par= .TRUE.
! The dimension of the file must be global (igextmin)
CALL ionc4_createfile(fileres,lon2d_g(igextmin(nb):igextmax(nb):stepi(nb),jgextmin(nb):jgextmax(nb):stepj(nb)), &
lat2d_g(igextmin(nb):igextmax(nb):stepi(nb),jgextmin(nb):jgextmax(nb):stepj(nb)), &
igextmin(nb),igextmax(nb),stepi(nb), &
jgextmin(nb),jgextmax(nb),stepj(nb), &
kextmin(nb),kextmax(nb),stepk(nb), &
kmax,0,sigecrit,l_out_nc4par= .TRUE.,comm_active=comm_zoom)
ELSE
! If none l_out_nc4par argument, l_out_nc4par is considered as false
! Each cpu create its own output file inside the local domain (iextmin)
CALL ionc4_createfile(fileres,lon2d(iextmin(nb):iextmax(nb):stepi(nb),jextmin(nb):jextmax(nb):stepj(nb)), &
lat2d(iextmin(nb):iextmax(nb):stepi(nb),jextmin(nb):jextmax(nb):stepj(nb)), &
iextmin(nb),iextmax(nb),stepi(nb),jextmin(nb),jextmax(nb),stepj(nb), &
kextmin(nb),kextmax(nb),stepk(nb),kmax,0,sigecrit)
ENDIF
END IF
END SUBROUTINE output_save
Libération du communicateur crée après création du fichier:
IF_MPI (l_out_nc4par .AND. communicator/=MPI_COMM_MARS) CALL MPI_COMM_FREE(communicator,ierr_mpi)
Moyenne zonale¶
Pour faire des moyennes zonales (ou méridiennes), il est aussi nécéssaire de créer de nouveau communicateur. Comme ce type de moyenne est classique, la librairie MPI gère directement cela en dégénéresçant une topologie cartésienne 2D ou 3D de processus en une topologie cartésienne respectivement 1D ou 2D.
- Pour MPI, dégénérer une topologie cartésienne 2D (ou 3D) revient à créer autant de communicateurs qu’il y a de lignes ou de colonnes (resp. de plans) dans la grille cartésienne initiale.
- L’intérêt majeur est de pouvoir effectuer des opérations collectives restreintes à un sous-ensemble de processus appartenant à :
- une même ligne (ou colonne), si la topologie initiale est 2D ;
- un même plan, si la topologie initiale est 3D.
Deux exemples de distribution de données dans une topologie 2D dégénérée:
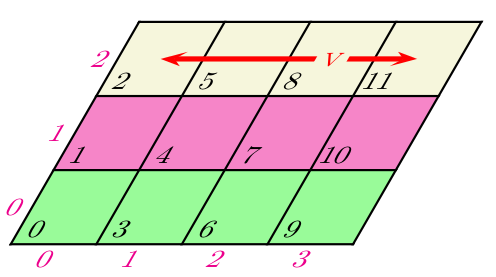
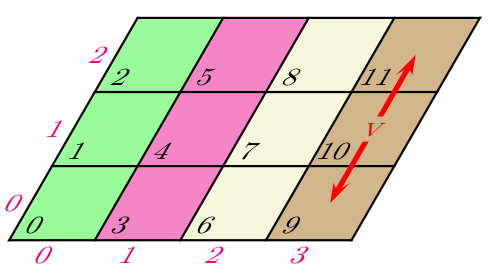
idris (Dupays, Flé, Gaidamour, Lecas)
Disponibilité des routines suivantes dans toolmpi.F90:
CREATE_COMM_ZONAL
ADD_ZONAL_RSH(sal_zonal,1,kmax,ljminm1,ljmaxp2,comm_zonal)
Elles sont utilisées dans la routine nudging.F90 (cas test ACC)
La subroutine CREATE_COMM_ZONAL permet de créer subdivision d’une topologie cartésienne:
SUBROUTINE CREATE_COMM_ZONAL(COMM_ZONAL,comm2dverif)
INTEGER, INTENT(INOUT) :: comm_zonal
INTEGER, INTENT(INOUT), OPTIONAL :: comm2dverif
INTEGER :: comm1d,comm2d
INTEGER,PARAMETER :: ndim2d=2
INTEGER, DIMENSION(ndim2d) :: dim2d
LOGICAL, DIMENSION(ndim2d) :: period,subdivision
LOGICAL :: reorder
! create a topology (2D)
dim2d(2)=MAXIPROC+1
dim2d(1)=MAXJPROC+1
period(:)=.FALSE.
reorder=.FALSE.
CALL
CMPI_CART_CREATE(MPI_COMM_MARS,ndim2d,dim2d,period,reorder,comm2d,IERR_MPI)
! moyenne zonale : chaque ligne de la topologie 2D (ou ligne de
! processeurs) est une topologie cartesienne 1D
! Subdivisions inversees car Tina a range les cpus dans ordre i
! croisant et non j croissant
subdivision(1)=.FALSE. ! Tina a range les cpus dans ordre i croisant et non j croissant
subdivision(2)=.TRUE.
CALL MPI_CART_SUB(comm2d,subdivision,comm1d,IERR_MPI)
comm_zonal=comm1d
PRINT_DBG*,'exit CREATE_COMM_ZONAL'
END SUBROUTINE CREATE_COMM_ZONAL
La subroutine ADD_ZONAL_RSH permet XXX classiques
Divers¶
start/end MPI
L’appel et la fermeture à la parallélisation MPI se fait ainsi:
INCLUDE 'mpif.h'
INTEGER :: ierr_mpi
CALL MPI_INIT(IERR_MPI) (depuis la routine MPI_START1)
code parallélisé
CALL_MPI MPI_FINALIZE(IERR_MPI) (fin main.F90 ou avant un STOP)
routines utiles pendant l’implémentation de la parallélisation MPI
Les routines suivantes ne sont utiles que pendant la mise en place de la parallélisation MPI. Aujourd’hui, on ne devrait plus avoir besoin de les appeller.
- mpi_exchange_rsh/rlg
Cette routine est appelée quand on a besoin de connaître les valeurs de jmin à jmax.
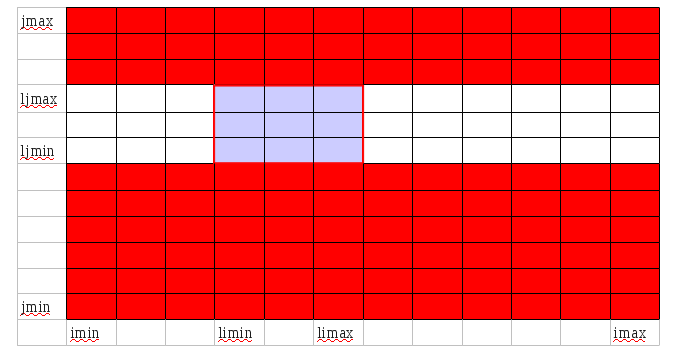
CALL exchange_rsh(Y ,kmax)
Warning
Cette fonction ne marche pas pour une décomposition en domaines MPI 2D. Elle ne marche que pour un découpage en bandes verticales.
- mpi_exchange_i
Cette routine est appelée quand on a besoin de connaître les valeurs de imin à imax.
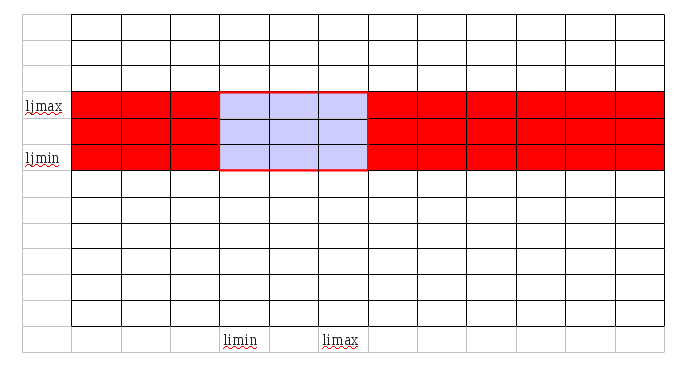
CALL exchange_i_rsh(Y(:,:,ljmin:ljmax),kmax)
- mpi_exchange i and j
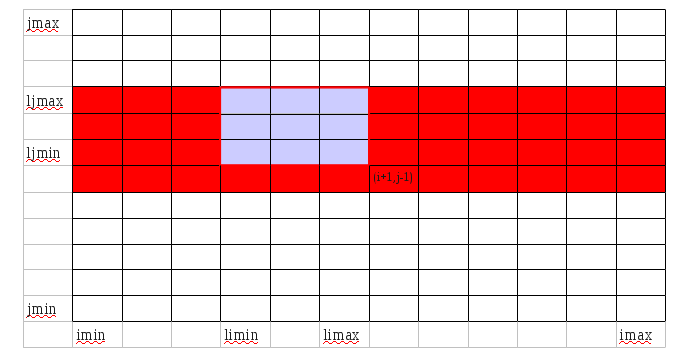
CALL exchange_i_rsh(Y(:,:,ljmin:ljmax),kmax) CALL ex_j_rsh(-1,0,kmax,imin, imax, ljminm1, ljmax, Y(:, imin:imax, ljminm1:ljmax))
Warning
Ne pas utiliser exchange_i_rsh avec d’autres indices que ljmin et ljmax. Donc ne pas écrire “CALL exchange_i_rsh(Y(:,:,ljminm1:ljmax),kmax)”