OpenMP¶
Note
Cette description du paradigme de parallélisation de openMP est très largement inspirée du cours de l’idris de Jalel Chergui et Pierre-François Lavallée. Merci à tous les deux pour leur travail de formation et leur choix de partager les connaissances en acceptant volontiers que leurs supports de cours soient réutilisés.
Présentation de OMP¶
- Paradigme de parallélisation pour architecture à mémoire partagée basé sur des directives à insérer dans le code source (C, C++, Fortran).
- OpenMP est constitué d’un jeu de directives, d’une bibliothèque de fonctions et d’un ensemble de variables d’environnement.
- OpenMP fait partie intégrante de tout compilateur Fortran/C/C++ récent.
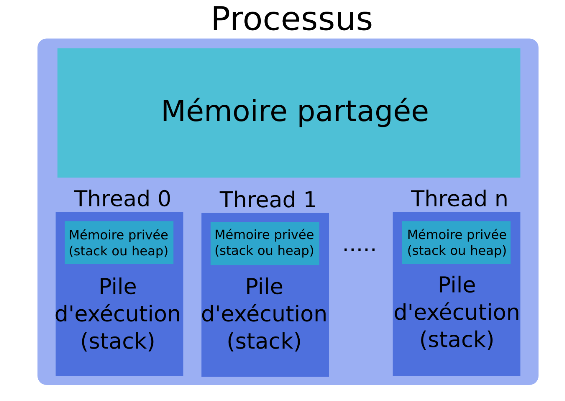
- Il permet de gérer :
- la création des processus légers,
- le partage du travail entre ces processus légers,
- les synchronisations (explicites ou implicites) entre tous les processus légers,
- le statut des variables (privées ou partagées).
idris (Lavallée & Wautelet)
Limitation de OMP¶
- L’extensibilité du code parallèle est physiquement limitée par la taille du nœud à mémoire partagée sur lequel il s’exécute.
- En pratique, la bande passante mémoire cumulée à l’intérieur d’un nœud SMP peut encore plus limiter le nombre de cœurs utilisables efficacement. Les contentions dues à la limitation de la bande passante mémoire peuvent souvent être levées en optimisant l’utilisation des caches.
- Attention aux surcoûts implicites d’OpenMP lors de la création des processus légers, de la synchronisation entre les processus légers (implicite ou explicite) ou du partage du travail comme le traitement des boucles parallèles par exemple.
- OpenMP n’est pas adapté à des problématiques dynamiques (i.e. dont la charge de travail évolue rapidement au cours de l’exécution).
- Comme pour n’importe quelle parallélisation de code, l’accélération finale sera limitée par la partie purement séquentielle du code.
Approche utilisée dans MARS: l’approche classique Fine-grain¶
Définition: OpenMP grain fin ou Fine-grain (FG) : utilisation des directives OpenMP pour partager le travail entre les threads, en particulier au niveau des boucles parallèles avec la directive DO.
Avantages¶
- Simplicité de mise en oeuvre ; la parallélisation ne dénature pas le code ; une seule version du code à gérer pour la version séquentielle et parallèle.
- Une approche incrémentale de la parallélisation du code est possible.
- Si on utilise les directives OpenMP de partage du travail (WORKSHARE, DO, SECTION), alors des synchronisations implicites gérées par OpenMP simplifient grandement la programmation (i.e. boucle parallèle avec réduction).
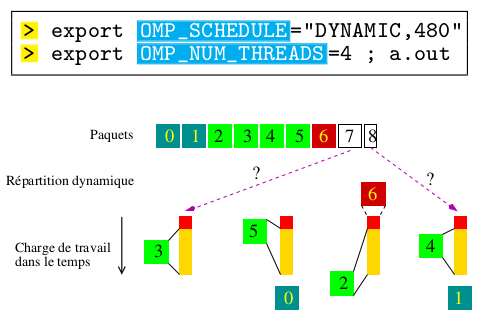
- Sur les boucles parallèles, un équilibrage dynamique de charge peut être réalisé via les options de la clause SCHEDULE (DYNAMIC, GUIDED).
Inconvénients¶
- Les surcoûts dus au partage du travail et à la création/gestion des threads peuvent se révéler importants, particulièrement lorsque la granularité du code parallèle est petite/faible. Cet inconvénient général n’est pas vrai pour MARS, car la parallélisation se fait sur les boucles j et non sur k (et la dimension j est en général élevée)
- Certains algorithmes ou nids de boucles peuvent ne pas être directement parallélisables car ils requièrent des synchronisations plus fines que de simples barrières, exclusions mutuelles ou exécution single. (La diffusion horizontale rotiationnée est actuellement le seul example dans MARS. Il faut alors utiliser l’approche Coarse-Grain. Cette approche n’est pas traitée dans cette documentation. Se reporter au cours de l’idris sur la parallélisation hybride)
- Dans la pratique, on observe une extensibilité limitée des codes (en tout cas inférieure à celle du même code parallélisé avec MPI), même lorsqu’ils sont bien optimisés. Plus la granularité du code est fine, plus ce phénomème s’accentue.
Compilation¶
OpenMP faisant partie intégrante de tout compilateur Fortran/C/C++ récent, il suffit d’ajouter l’option de compilation suivante:
0MP = -openmp
Exécution¶
Préciser le nombre de threads OMP utilisés dans le batch de lancement en utilisant la variable d’environnement OMP_THREADS:
setenv OMP_THREADS 8
Préciser le type de distribution des tâches en utilisant la variable d’environnement OMP_SCHEDULE:
setenv OMP_SCHEDULE "dynamic,1"
setenv OMP_SCHEDULE "dynamic,3"
setenv OMP_SCHEDULE "static,20"

Etendue d’une région parallèle¶
L’influence (ou la portée) d’une région parallèle entre les directives:
a=3 ; b=6
!$OMP PARALLEL
x=a+b
CALL routine
!$OMP END PARALLEL
et s’étend aussi bien au code contenu lexicalement dans cette région (étendue statique), qu’au code des sous-programmes appelés. L’union des deux représente « l’étendue dynamique ».
Il existe une barrière implicite de synchronisation en fin de région parallèle.
L’approche incrémentale de la parallélisation du code est donc facile.
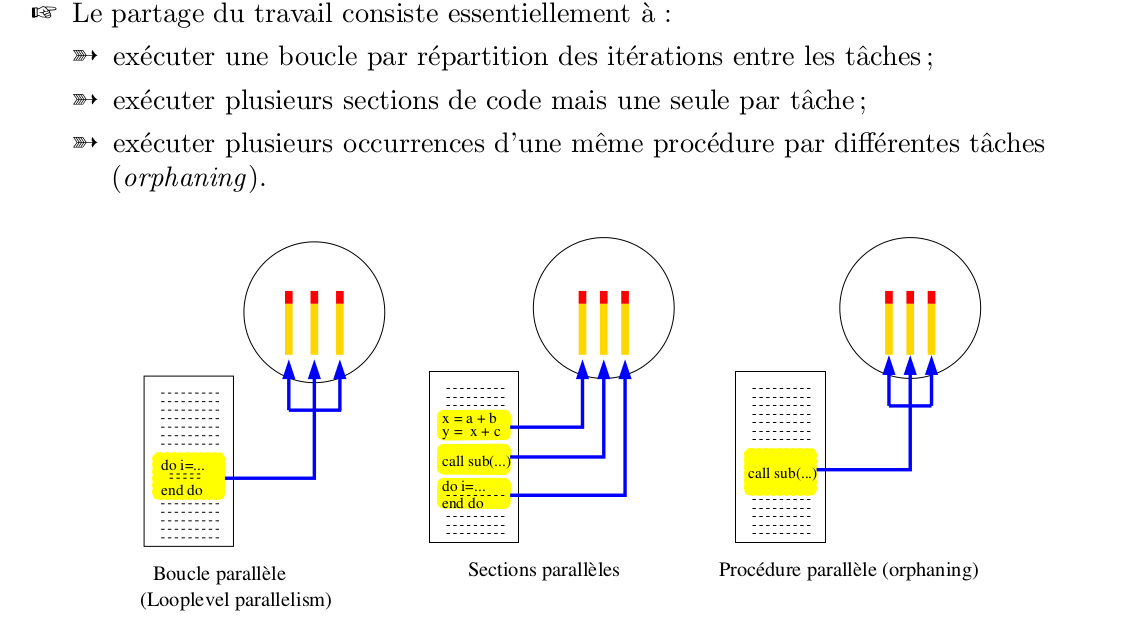
Partage du travail¶
Au sein d’une même région parallèle, toutes les tâches concurrentes exécutent le même code. On utilise les directive !$OMP DO et !$OMP SECTION pour partager le travail. Pour s’assurer qu’une portion de code n’est effectué que par un seul thread (le premier disponible), on inserre cette partie entre les directives !$OMP SINGLE et !$OMP END SINGLE.
Boucles parallèles¶
- C’est un parallélisme par répartition des itérations d’une boucle.
- La boucle parallélisée est celle qui suit immédiatement la directive DO.
- Les boucles « infinies » et do while ne sont pas parallélisables avec OpenMP.
- Le mode de répartition des itérations peut être spécifié dans la clause SCHEDULE.
- Le choix du mode de répartition permet de mieux contrôler l’équilibrage de la charge de travail entre les tâches.
- Les indices de boucles sont des variables entières privées.
- Par défaut, une synchronisation globale est effectuée en fin de construction END DO à moins d’avoir spécifié la clause NOWAIT.
- Il est possible d’introduire autant de constructions DO (les unes après les autres) qu’il est souhaité dans une région parallèle.

idris (Chergui & Lavallée)

idris (Chergui & Lavallée)
idris (Chergui & Lavallée)
Sections parallèles¶
Non utilisées dans le code MARS. A tord, elles devraient l’être dans les routines de lecture, en particulier sflxread.F90
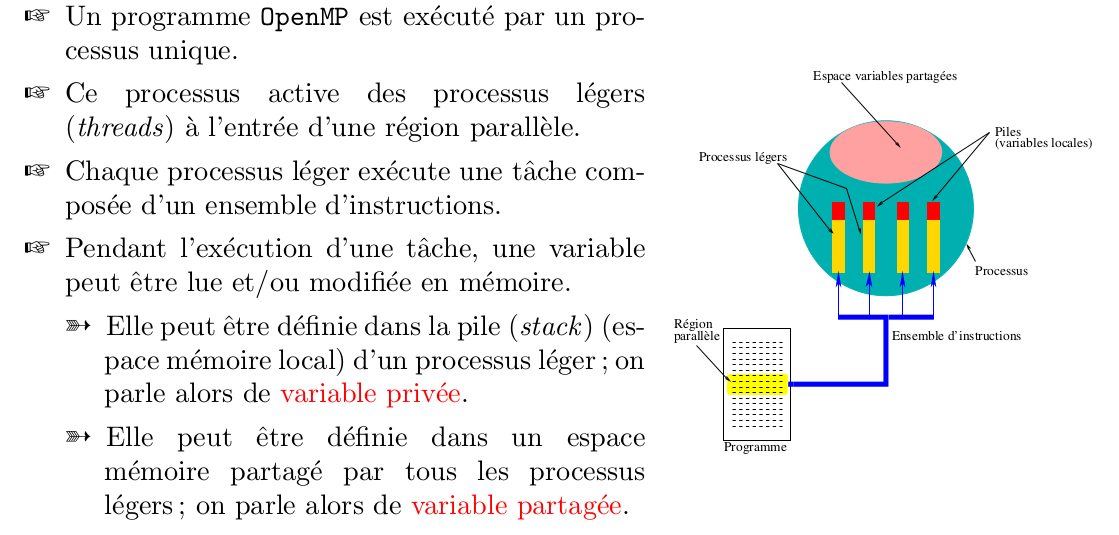
Variables privées / partagées¶
variables privées (statut PRIVATE): variable se trouvant dans la pile de chaque thread donc inconnu des autres threads. Sa valeur est indéfinie à l’entrée d’une région parallèles.
variables partagées (statut SHARED): variable se trouvant dans la mémoire partagée et accessible par tous les threads. ce sont par défaut toutes les variables statiques (emplacement de mémoire défini à la déclaration par le compilateur), issues des commons ou modules (définies comme PUBLIC) ou SAVE ou PARAMETER ou DATA...

idris (Chergui & Lavallée)
- Dans une région parallèle, par défaut, le statut des variables est partagé.
- Dans un sous-programme appelé dans une région parallèle, les variables locales et automatiques sont implicitement privées à chacune des tâches (elles sont définies dans la pile de chaque tâche).
- Dans une subroutine, toutes les variables transmises par argument (dummy parameters) héritent du statut défini dans l’étendue lexicale (statique) de la région.
USE comvars, ONLY: temp,ssh,limin,limax,imin,imax
INTEGER :: i,j,a,b,c
REAL(KIND=4), DIMENSION(kmax,imin:imax) :: section
a=1000
!$OMP PARALLEL DEFAULT(NONE) &
!$OMP& FIRSTPRIVATE(a) &
!$OMP& PRIVATE(i,j,section) &
!$OMP& SHARED(ljmin,ljmax,limin,limax,ssh,temp)
!$OMP DO SCHEDULE(RUNTIME)
DO j=ljmin,ljmax
DO i=limin,limax
DO k=1,kmax
temp(k,i,j)=...
a=ssh(i,j)
section(k,i)=
END DO
END DO
END DO
!$OMP END DO
Lancement d’un job OMP sur Caparmor¶
qsub batch_omp