MPI+OMP¶
L’introduction de la parallélisation hybride dans le code MARS a été effectuée par Tina Odaka.
Note
Merci à Pierre-Francois Lavallée et Philippe Wautelet pour leur supports didactiques et leur autorisation à exploiter une partie de leurs cours disponibles sous le lien cours idris .
Présentation¶
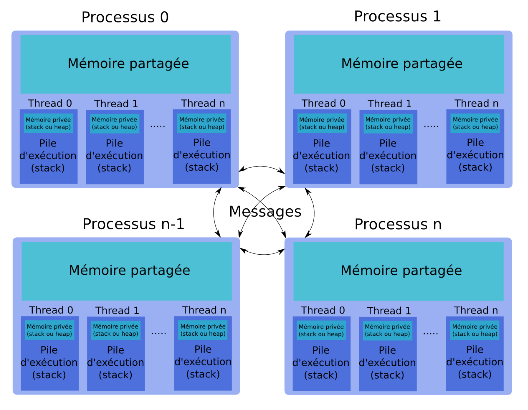
idris (Lavallée & Wautelet)
La commande MPI_Init() est remplacée par MPI_Init_thread(). Ainsi on peut exploiter différents types de parallélisation:
- MPI_THREAD_SINGLE : OpenMP ne peut pas être utilisé
- MPI_THREAD_FUNNELED : les appels MPI doivent être faits en dehors des régions parallèles OpenMP ou dans les regions OpenMP master ou dans des zones protégées par un appel à MPI_Is_thread_main
- MPI_THREAD_SERIALIZED : dans les régions parallèles OpenMP, les appels MPI doivent être réalisés dans des sections critical (si nécessaire pour garantir un seul appel MPI simultané)
- MPI_THREAD_MULTIPLE : aucune restriction
Codage dans MARS¶
Dans MARS, MPI_Init() est utilisé en hybrid, et la parallélisation a été implémenté en type MPI_THREAD_FUNNELED ce qui donne pour les échanges MPI (le reste est inchangé):
Dans une région parallèle OMP:
OMPMPI barrier
OMPMPI master
CALL_MPI ex_i_rsh(-1,0,kmax,liminm1,limax ,ljminm1,ljmax ,vish_phi(:,liminm1:limax ,ljminm1:ljmax ))
CALL_MPI ex_j_rsh(-1,0,kmax,liminm1,limax ,ljminm1,ljmax ,vish_phi(:,liminm1:limax ,ljminm1:ljmax ))
CALL_MPI ex_i_rsh( 0,1,kmax,limin ,limaxp1,ljmin ,ljmaxp1,vish_xe (:,limin :limaxp1,ljmin :ljmaxp1))
CALL_MPI ex_j_rsh( 0,1,kmax,limin ,limaxp1,ljmin ,ljmaxp1,vish_xe (:,limin :limaxp1,ljmin :ljmaxp1))
OMPMPI end master
OMPMPI barrier
OMPMPI flush(vish_phi,vish_xe)
qui devient avec pré-processing
!$OMP barrier
!$OMP master
CALL ex_i_rsh(-1,0,kmax,liminm1,limax ,ljminm1,ljmax ,vish_phi(:,liminm1:limax ,ljminm1:ljmax ))
CALL ex_j_rsh(-1,0,kmax,liminm1,limax ,ljminm1,ljmax ,vish_phi(:,liminm1:limax ,ljminm1:ljmax ))
CALL ex_i_rsh( 0,1,kmax,limin ,limaxp1,ljmin ,ljmaxp1,vish_xe (:,limin :limaxp1,ljmin :ljmaxp1))
CALL ex_j_rsh( 0,1,kmax,limin ,limaxp1,ljmin ,ljmaxp1,vish_xe (:,limin :limaxp1,ljmin :ljmaxp1))
!$OMP end master
!$OMP barrier
!$OMP flush(vish_phi,vish_xe)
En dehors d’une région parallèle OMP:
!$OMP END PARALLEL
CALL_MPI ex_i_rsh(0,1,kmax,limin,limaxp1,ljmin,ljmaxp1,nz(:,limin:limaxp1,ljmin:ljmaxp1))
CALL_MPI ex_j_rsh(0,1,kmax,limin,limaxp1,ljmin,ljmaxp1,nz(:,limin:limaxp1,ljmin:ljmaxp1))
CALL_MPI ex_i_rsh(-1,1,kmax,liminm1,limaxp1,ljminm1,ljmaxp1,kz(:,liminm1:limaxp1,ljminm1:ljmaxp1))
CALL_MPI ex_j_rsh(-1,1,kmax,liminm1,limaxp1,ljminm1,ljmaxp1,kz(:,liminm1:limaxp1,ljminm1:ljmaxp1))
Intérêt¶
- La programmation hybride permet d’optimiser l’adéquation du code à l’architecture cible. Cette dernière est généralement constituée de nœuds à mémoire partagée (SMP) reliés entre eux par un réseau d’interconnexion. L’intérêt de la mémoire partagée au sein d’un nœud est qu’il n’est pas nécessaire de dupliquer des données pour se les échanger. Chaque thread a visibilité sur les données SHARED.
- Les mailles fantômes ou halo, introduites pour simplifier la programmation de codes MPI utilisant une décomposition de domaine, n’ont plus lieu d’être à l’intérieur du nœud SMP. Seules les mailles fantômes associées aux communications inter-nœuds sont nécessaires.
- Le gain associé à la disparition des mailles fantômes intra-nœud est loin d’être négligeable. Il dépend fortement de l’ordre de la méthode utilisée, du type de domaine (2D ou 3D), du type de décomposition de domaine (suivant une seule dimension, suivant toutes les dimensions) et du nombre de cœurs du nœud SMP.
- L’empreinte mémoire des buffers systèmes associés à MPI est non négligeable et croît avec le nombre de processus. Par exemple, pour un réseau Infiniband avec 65.000 processus MPI, l’empreinte mémoire des buffers systèmes atteint 300 Mo par processus, soit pratiquement 20 To au total !
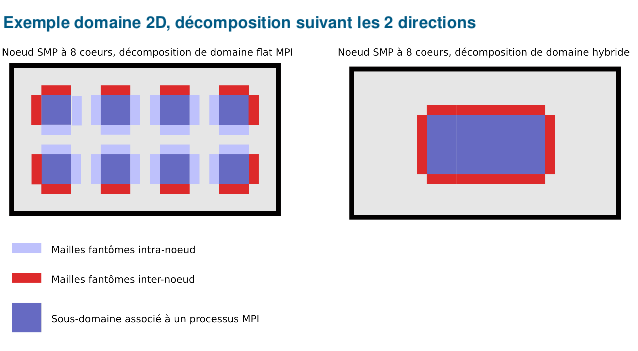
idris (Lavallée & Wautelet)
Efficacité¶
Approche MPI_THREAD_FUNNELED :
- On augmente la bande passante réseau réellement utilisée en augmentant le nombre de processus MPI par nœud (i.e. on génère autant de flux de communication en parallèle que de processus MPI par nœud).
- La solution basique consistant à utiliser autant de threads OpenMP que de cœurs au sein d’un nœud et autant de processus MPI que de nœuds n’est généralement pas la meilleure les ressources n’étant pas utilisées de façon optimale, en particulier le réseau...
- On cherche à déterminer la valeur optimale du ratio entre le nombre de processus MPI par nœud et le nombre de threads OpenMP par processus MPI. Plus ce ratio est grand, meilleur est le débit du réseau inter-nœud, mais moins bonne est la granularité... Un compromis est à trouver.
- Le nombre de processus MPI (i.e. de flux de données à gérer simultanément) nécessaire pour saturer le réseau varie fortement d’une architecture à une autre.
- Cette valeur pourra être un bon indicateur du ratio optimal du nombre de processus MPI/nombre de threads OpenMP par nœud d’une application hybride.
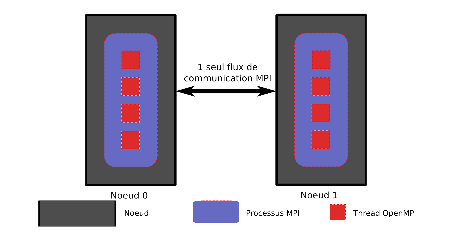
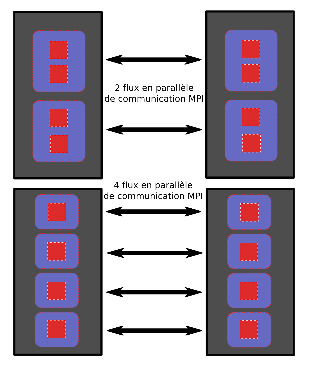
idris (Lavallée & Wautelet)
Il faut tester sur chaque configuration et plate-forme.
.
Compilation¶
Lancement d’un job hybrid sur Caparmor¶
- ::
- runmpi_connect name_run champs 256 8 0
runmpi_connect name_run name_file number_cpu number_omp type_file [concatdir]
- name_run: visible from qstat command
- name_file: ‘name defined in output.dat’_’suffix defined in paracom.txt’
- number_cpu: total number of cpus (MPI+OMP)
- number_omp: number of threads in each process (<=8 on caparmor)
- type_file: * 0 (no gathering because l_out_nc4par=.true.) * 1 (all records in one file) * 2 (a record by file)
- concatdir (optional): path where you will create the global file. To gather files faster, it is better to write CPU parts into a global file created under a /home directory.